






Les données privées ne sont jamais anonymes, démontrent des chercheurs belges
Selon une étude, la probabilité de ré-identifier avec certitude une personne sur base de quelques données socio-démographiques anonymisées, est de 99,98 %.



Les données privées ne sont jamais anonymes. C’est ce que démontrent, dans une étude publiée ce mercredi dans Nature Communications, Luc Rocher (chercheur FNRS au pôle d’ingénierie mathématique de l’UCLouvain), Yves-Alexandre de Montjoye (ingénieur diplômé de l’UCLouvain, passé par le MIT et aujourd’hui professeur assistant au Imperial College London) et Julien M. Hendrickx (professeur en ingénierie mathématique à l’UCLouvain). Une prouesse d’ingénierie mathématique démontre précisément que la probabilité de ré-identifier avec certitude une personne sur base de quelques données socio-démographiques anonymisées, est de 99,98 %. En clair : non seulement on peut retrouver n’importe qui, mais la certitude d’avoir trouvé la bonne personne est quasi-totale.
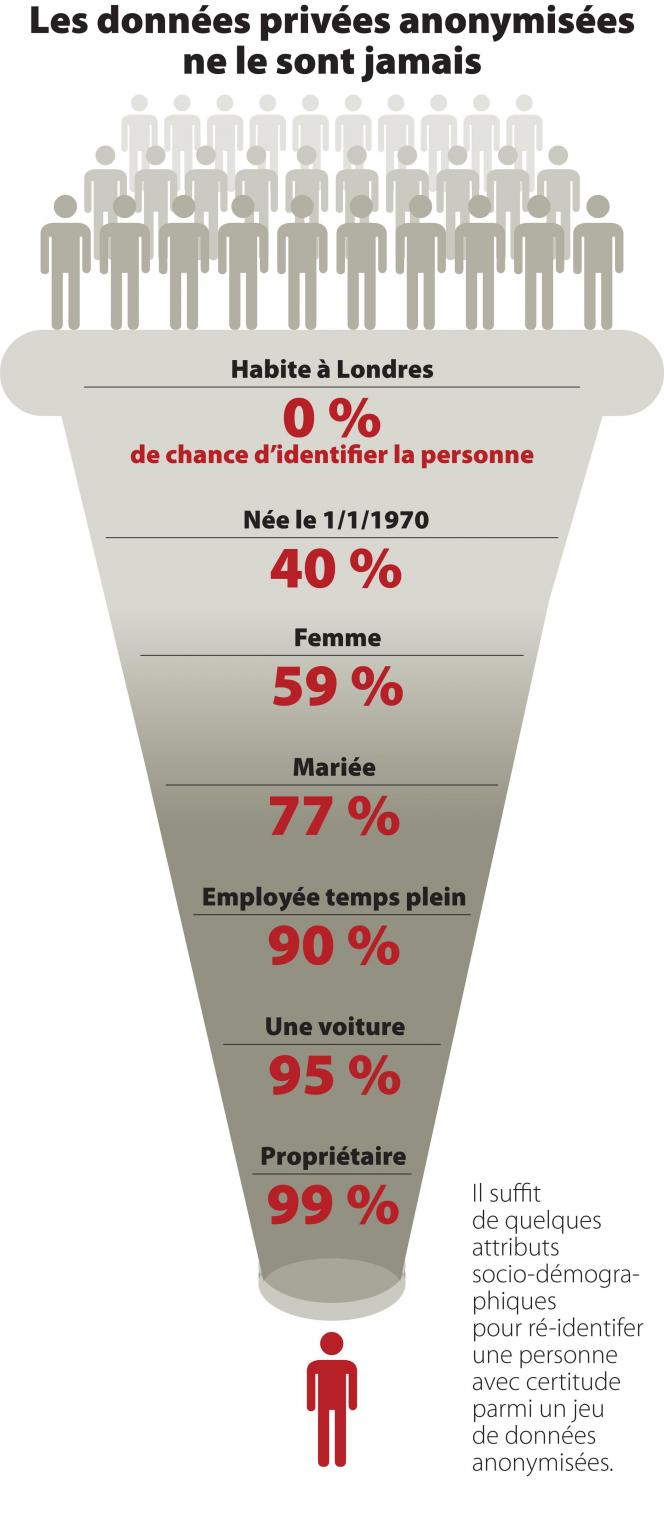
Selon Luc Rocher, « les algorithmes de désidentification ont fonctionné. Mais depuis une dizaine d’années, le type de données que l’on collecte n’a plus rien à voir. Les procédés d’anonymisation ne permettent plus de protéger la vie privée. Notre article dit qu’effectivement on n’est jamais certain. Mais dès lors que l’on sait que l’on a un homme, qui a 30 ans, qui habite à Saint-Gilles, qui est né un 5 janvier, qui a une voiture de sport rouge, qui a deux enfants, du coup, la probabilité que cela décrive correctement quelqu’un d’autre que la personne que je recherche est extrêmement faible. » Dit autrement : la probabilité d’avoir identifié la personne est quasi totale. 99,98 % de certitude selon l’étude. Il suffit de 15 attributs pour retrouver une personne sur l’entièreté de la population américaine.
► De quoi remettre en cause le RGDP? Les explications des chercheurs sur Le Soir+







Pour poster un commentaire, merci de vous abonner.
S'abonnerQuelques règles de bonne conduite avant de réagir7 Commentaires